In the previous post we saw how to merge two or more historical tables with a T-Sql script. We will now propose a different solution to the problem that also takes into account the presence of gaps in the validity periods of the records.
We’ll start from the same test database we used for the previous post, so you can go and get the same SQL script to create the test tables we need.
Another solution…
First of all, in this solution, we are going to put all start dates and all end dates in a row. Below is the query that performs this task:
WITH DATES
AS
(
SELECT E.ID AS EmployeeID, E.HireDate AS DATE_CHANGE
FROM Employees E
UNION
SELECT E.ID, DATEADD(DD, 1, E.EndDate)
FROM Employees E
WHERE E.EndDate IS NOT NULL
UNION
SELECT HC.EmployeeID, HC.FromDate
FROM HistEmpCompany HC
UNION
SELECT HC.EmployeeID, DATEADD(DD, 1, HC.ToDate)
FROM HistEmpCompany HC
WHERE HC.ToDate IS NOT NULL
UNION
SELECT HD.EmployeeID, HD.FromDate
FROM HistEmpDept HD
UNION
SELECT HD.EmployeeID, DATEADD(DD, 1, HD.ToDate)
FROM HistEmpDept HD
WHERE HD.ToDate IS NOT NULL
)
SELECT *
INTO #DATES
FROM DATES;In this way we have a list of dates when something, in this step we don’t know what, has been changed. Note the call to DATEADD in the queries that extract the end date of the validity periods: this is necessary because something could change also the day after the day following the end of a period. This could create duplicates rows if adjacent periods exist, but the UNION operator will remove them.
The next step involves assigning an ID to each row of the table. The ID will be unique within an employee, so we may find the same ID across different employees. This ID will be used to assign each start date an end date, calculated as the start date minus one day of the following period.
Here is the code for this second step:
WITH DATES_WITH_ID
AS
(
SELECT ROW_NUMBER()
OVER(PARTITION BY D.EmployeeID ORDER BY D.DATE_CHANGE) AS ROW_ID,
D.EmployeeID,
D.DATE_CHANGE
FROM #DATES D
)
SELECT *
INTO #DATES_WITH_ID
FROM DATES_WITH_IDAnd now we are ready to rebuild our validity periods:
SELECT T1.ROW_ID,
T1.EmployeeID,
T1.DATE_CHANGE AS DATE_START,
DATEADD(DD, -1, T2.DATE_CHANGE) AS DATE_END
INTO #PERIODS
FROM #DATES_WITH_ID T1
LEFT JOIN #DATES_WITH_ID T2 ON T1.EmployeeID = T2.EmployeeID
AND T1.ROW_ID = (T2.ROW_ID - 1)If you execute the following query:
SELECT *
FROM #PERIODS
ORDER BY EmployeeID, DATE_STARTand look at the table #PERIODS, you will see the following:
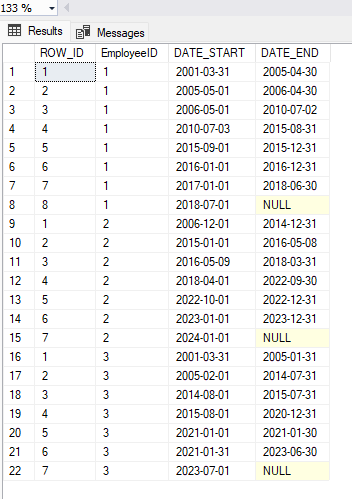
As said before, we have built a table with all the employee periods. Now for each period we must take the values we need from historical tables. To do this simply take the value at the beginning of the period, as in the following query:
DECLARE @MAX_DATE DATETIME = '99991231'
SELECT E.ID, T.EmployeeID,
E.LastName, E.LastName, HC.CompanyName, HD.DeptName,
T.DATE_START, T.DATE_END
FROM #PERIODS T
LEFT JOIN Employees E ON T.EmployeeID = E.ID
AND T.DATE_START BETWEEN E.HireDate AND ISNULL(E.EndDate, @MAX_DATE)
LEFT JOIN HistEmpCompany HC ON T.EmployeeID = HC.EmployeeID
AND T.DATE_START BETWEEN HC.FromDate AND ISNULL(HC.ToDate, @MAX_DATE)
LEFT JOIN HistEmpDept HD ON T.EmployeeID = HD.EmployeeID
AND T.DATE_START BETWEEN HD.FromDate AND ISNULL(HD.ToDate, @MAX_DATE)
ORDER BY T.EmployeeID, T.DATE_STARTThis is the final result:
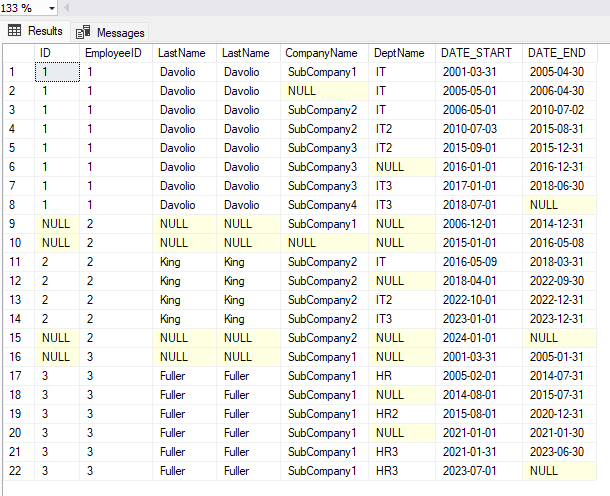
Let’s analyze the result
Let’s look at some special cases in our final result. Take for example row number 2 where we have a NULL in the company field in period 2005-05-01 to 2006-04-30. This is correct, since if you look at the historical table HistEmpCompany you will see that has a gap for employee Davolio from 2005-05-01 to 2006-04-30.
If you look carefully, you will see that there are rows with the ID, Last name, First name fields NULL. Why this? We might consider this an anomaly in source data. Employees King and Fuller were hired on 2016-05-09 and 2005-02-01 respectively but their historical tables start from dates that are prior to the their hire date. This explains their gaps in the columns containing ID, Last name and Full name.
I also want you to point out line 15: the employee King quit on 2023-12-31 but his company’s history is still open (that is has NULL in the field ToDate). Row 15 correctly report this since it has all fields but company set to NULL. The field “company” correctly contains the value “Subcompany 1”.
Just one last thing before we close: execute this update to set the end date of the last record in company history for employee King:
UPDATE HistEmpCompany SET ToDate = '20231231' WHERE EmployeeID = 2 AND CompanyName = 'SubCompany2'Now if you run the script again you will see the following output:
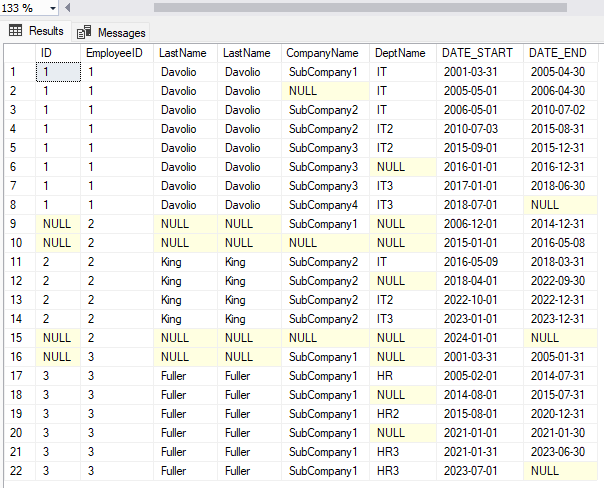
At row 15, apart for date start equals to 2024-01-01, we now have all NULL values. This is correct because all histories for that employee are closed as of 2023-12-31 and therefore there is no data to show. If you want you can get rid of this kind of record adding adding one more step to the query.
This is the final complete version of the script containing this last step:
DROP TABLE IF EXISTS #DATES;
DROP TABLE IF EXISTS #DATES_WITH_ID;
DROP TABLE IF EXISTS #PERIODS;
WITH DATES
AS
(
SELECT E.ID AS EmployeeID, E.HireDate AS DATE_CHANGE
FROM Employees E
UNION
SELECT E.ID, DATEADD(DD, 1, E.EndDate)
FROM Employees E
WHERE E.EndDate IS NOT NULL
UNION
SELECT HC.EmployeeID, HC.FromDate
FROM HistEmpCompany HC
UNION
SELECT HC.EmployeeID, DATEADD(DD, 1, HC.ToDate)
FROM HistEmpCompany HC
WHERE HC.ToDate IS NOT NULL
UNION
SELECT HD.EmployeeID, HD.FromDate
FROM HistEmpDept HD
UNION
SELECT HD.EmployeeID, DATEADD(DD, 1, HD.ToDate)
FROM HistEmpDept HD
WHERE HD.ToDate IS NOT NULL
)
SELECT *
INTO #DATES
FROM DATES;
WITH DATES_WITH_ID
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY D.EmployeeID
ORDER BY D.DATE_CHANGE) AS ROW_ID,
D.EmployeeID,
D.DATE_CHANGE
FROM #DATES D
)
SELECT *
INTO #DATES_WITH_ID
FROM DATES_WITH_ID
SELECT T1.ROW_ID, T1.EmployeeID,
T1.DATE_CHANGE AS DATE_START, DATEADD(DD, -1, T2.DATE_CHANGE) AS DATE_END
INTO #PERIODS
FROM #DATES_WITH_ID T1
LEFT JOIN #DATES_WITH_ID T2 ON T1.EmployeeID = T2.EmployeeID
AND T1.ROW_ID = (T2.ROW_ID - 1)
SELECT P.EmployeeID, MAX(DATE_START) MAX_START_DATE
INTO #MAX_LAST_START_DATES
FROM #PERIODS P
GROUP BY P.EmployeeID
DECLARE @MAX_DATE DATETIME = '99991231'
SELECT E.ID, T.EmployeeID,
E.LastName, E.LastName,
HC.CompanyName, HD.DeptName,
T.DATE_START, T.DATE_END
FROM #PERIODS T
LEFT JOIN Employees E ON T.EmployeeID = E.ID
AND T.DATE_START BETWEEN E.HireDate AND ISNULL(E.EndDate, @MAX_DATE)
LEFT JOIN HistEmpCompany HC ON T.EmployeeID = HC.EmployeeID
AND T.DATE_START BETWEEN HC.FromDate AND ISNULL(HC.ToDate, @MAX_DATE)
LEFT JOIN HistEmpDept HD ON T.EmployeeID = HD.EmployeeID
AND T.DATE_START BETWEEN HD.FromDate AND ISNULL(HD.ToDate, @MAX_DATE)
WHERE (E.ID IS NOT NULL OR HC.CompanyName IS NOT NULL OR HD.DeptName IS NOT NULL)
OR EXISTS(SELECT *
FROM #MAX_LAST_START_DATES X
WHERE T.DATE_START < X.MAX_START_DATE)
ORDER BY T.EmployeeID, T.DATE_START
And this is the final result:
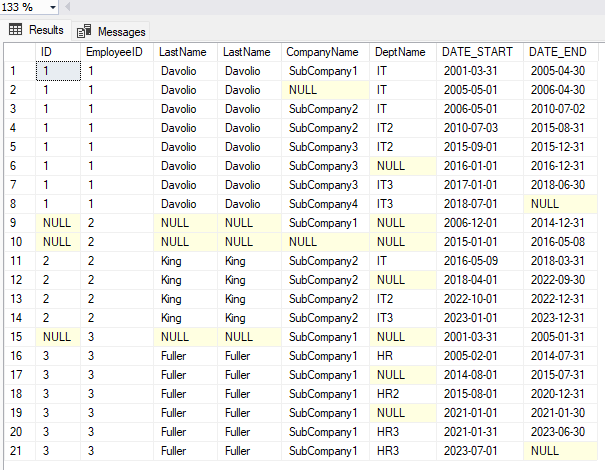
And at this point we can close…
I hope this long post will be useful to you and you can take inspiration to solve your problems related to historical data!